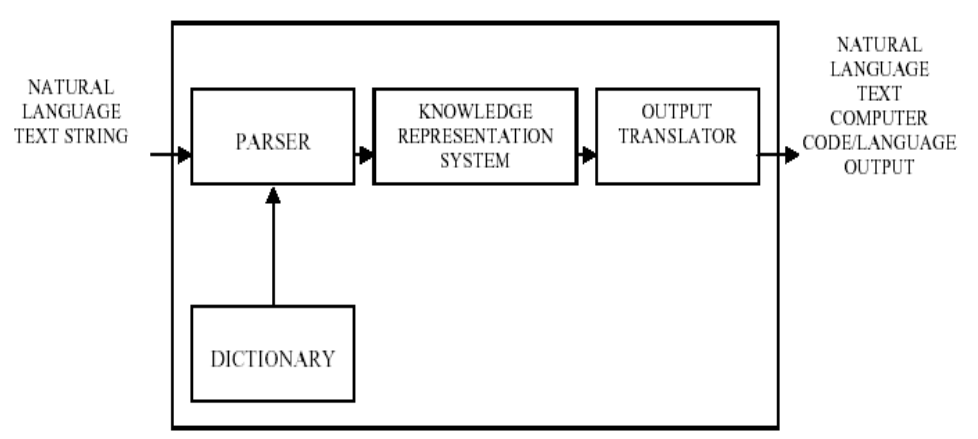
- Jumlah kata/dokumen teks yang sangat besar sehingga membutuhkan kemudahan dalam mendapatkan informasi teks tersebut
2. Definisi
- Teks merupakan ungkapan bahasa yang menurut isi dan paragmatik merupakan satu kesatuan
- Korups adalah badan dari teks yang muncul secara alami, biasanya dipilih dengan cara tertentu.
- Pemrosesan teks adalah proses menghitung dan mengurutkan kata pada teks
- Tokenisasi adalah proses pemotongan kumpulan karakter menjadi sebuah kata tunggal/toke
3. Contoh dokumen teks
- Teks media social, teks halaman web, status pada media social, teks pada jurnal.
- Korpus pada sebuah teks yang terdapat pada sebuah file. Misalnya yang berformat XML.
4. Karakterristik Dokumen

- A corpus of documents: Setiap sistem harus memutuskan dokumen yang ada akan diperlakukan sebagai apa. Bisa sebagai sebuah paragraf, halaman, atau teks multipage.
- Queries posed in a query language. Sebuah query menjelaskan tentang apa yang user ingin peroleh. Query language dapat berupa list dari kata-kata, atau bisa juga menspesifikasikan sebuah frase dari kata-kata yang harus berdekatan
- A result set. Ini adalah bagian dari dokumen yang dinilai oleh sistem IR sebagai yang relevan dengan query.
- A presentation of the result set. Maksud dari bagian ini adalah tampilan list judul dokumen yang sudah di ranking.
5. Contoh Proses dari Pemrosesan Teks
6. Pengolahan teks mencakup:
- Information Extraction : mengekstrak informasi yang dianggap penting dari suatu dokumen lowongan, walaupum memiliki format beragam dapat di ekstrak secara otomatis job title, tingkat pendidikan, penguasaan bahasa dsb.
- Text Summarization : menghasilkan ringkasan suatu dokumen secara otomatis.
- Data Mining : proses identifikasi valid, yang berpotensu berguna, dan pada akhirnya dapat dipahami pola data yang tersimpan dlam database yang terstruktur, dimana data diorganisir dalam catatan terstruktur dengan kategoru, ordinal, atau variable yang terus menerus.
- Text Mining (biasa dikenal juga dengan text data mining atau penemuan pengetahuan) dalam database tekstual adalah semi-otomatis proses ekstrksi pola (informasi yang berguna dan pengetahuan) dari sumber data yang tidak terstruktur dalam jumlah yang besar.
- Informatuon Retrival : pencarian dokumen (contoh google : search Engine)
- Document Clustering : mirip dengan klasifikasi document, hanya saja kelas dokumen tidak ditentukann sebelumnya. Misalnya berita tentang lalulintas dapat menjadi satu kelas dengan kelas berita criminal karena didalamnya banyak memuat tentang orang yang tewas, cedera,rumah sakit dsb.